
系统位数:64软件大小:417.69MB更新时间:2025-01-10
支持系统:WinAll软件语言:简体中文软件授权:免费软件
软件厂商:暴风集团
💠Illuminati💠欢迎使用kaiyun全站网页版登录,这是一款为您提供最新资讯、新闻和娱乐内容的综合平台。无论您是想了解当天的热点新闻,还是想追踪全球各地的流行趋势,这个App都能满足您的需求。智能推荐算法帮助您发现更感兴趣的内容,让您随时随地掌握一手信息。流畅的用户体验和简洁的设计让操作更轻松,快来探索吧!《kaiyun全站网页版登录》是一款可以实现手机音乐编辑的软件。该音频编辑软件应用程序支持MP3类型的音乐文件编辑,操作简单易学。它还可以合成多段音乐,通过音频剪辑专家应用程序玩家库随时提取音频、剪辑和编辑,并支持一键共享。

功能介绍
1、💠多任务处理:具备强大的多任务处理能力,用户可以同时运行多个应用程序,切换流畅,提升工作和娱乐的效率。
2、💠音乐播放器:内置高质量音乐播放器,支持多种音频格式和播放模式,提供出色的音质和丰富的音乐体验。
3、💠任务管理器:内置任务管理器,用户可以查看和管理正在运行的应用程序,提升系统性能和操作效率。
4、💠大容量存储:提供大容量内置存储空间,满足用户存储大量照片、视频、应用和文件的需求,同时还支持云存储扩展。
5、💠社交媒体应用:内置多种社交媒体应用,方便用户随时随地与朋友、家人和同事保持联系,分享生活中的点滴和重要时刻。
6、💠屏幕分享:支持屏幕分享功能,用户可以将手机屏幕内容投射到电视、电脑等大屏设备上,方便演示和娱乐。
7、💠语音留言功能:内置语音留言功能,用户可以随时录制和发送语音留言,方便与朋友、家人和同事交流。
8、💠快速应用启动:内置快速应用启动功能,用户可以通过快捷方式和手势快速打开常用应用,提高操作效率。分屏显示,支持LED大屏幕;
9、💠高精度指针输入:支持高精度指针输入功能,用户可以使用触控笔进行精细操作和绘图,适合创意设计和手写笔记。
10、💠音乐播放器:内置高质量音乐播放器,支持多种音频格式和播放模式,提供出色的音质和丰富的音乐体验。
11、💠文件管理器:内置文件管理器,用户可以方便地管理手机中的文件、图片、视频和应用,支持文件分类、搜索和分享。
12、💠快速文件共享:支持高速文件共享功能,用户可以通过蓝牙、WiFi或NFC快速分享照片、视频和文件,提升社交和工作效率。
13、💠智能省电:内置智能省电功能,根据使用习惯和场景自动优化电池使用,延长续航时间,提高电池寿命。
14、💠隐私保护模式:内置隐私保护模式,用户可以在需要时隐藏重要的应用和数据,防止他人窥探,保护个人隐私。
15、💠高清屏幕截图:内置高清屏幕截图功能,用户可以快速截取屏幕上的内容,并进行编辑和分享,提升信息记录和分享的便捷性。字幕显示;
16、💠防丢失提醒:支持防丢失提醒功能,当手机与配对设备距离过远时自动发出警报,帮助用户防止物品遗失。
17、💠防丢失提醒:支持防丢失提醒功能,当手机与配对设备距离过远时自动发出警报,帮助用户防止物品遗失。
18、💠蓝牙耳机配对:内置快速蓝牙耳机配对功能,用户可以轻松连接和管理蓝牙耳机,享受无线音频的便利和高质量音效。
19、💠节能模式:支持节能模式,优化系统和应用的耗电情况,延长电池续航时间,适合在电量不足时使用。
20、💠广告拦截:支持广告拦截功能,用户可以在浏览网页和使用应用时自动屏蔽烦人的广告,提高浏览体验。
21、💠儿童模式:内置儿童模式,提供安全的使用环境和适合儿童的应用和内容,帮助家长管理和控制儿童的手机使用。
22、💠反向查找功能:支持反向查找功能,用户可以通过手机快速找到遗失的物品,如钥匙、钱包等,提升生活便利性。
23、💠阅读模式:支持阅读模式,优化屏幕亮度和颜色,减轻眼睛疲劳,适合在长时间阅读电子书和文章时使用。



新增了「头像定制」功能,让您个性化设置应用头像。
添加了新的主题和壁纸,个性化您的应用界面。
引入了游戏中心,集中管理您的游戏应用。
优化了地图导航功能,提供更准确的路线规划。
优化了用户界面,使其更加直观和易于操作。
添加了健康提醒功能,定时提醒您进行健康活动。
📏kaiyun全站网页版登录7.57一款移动清洁应用,为用户提供简单实用的垃圾清洁功能,方便用户提高移动电话的运行速度,节约移动电话的功耗,方便用户使用移动电话,感兴趣的话就快来下载体验吧!
🦗kaiyun全站网页版登录6.66一款非常专业使用的手机打印软件,该软件适用于各种佳能打印机,使用佳能打印机APP可直接在手机上设置,选择图片文档等,并支持基本修改等操作,可在手机上控制打印。欢迎有需要的用户下载使用。
🌁kaiyun全站网页版登录1.71一款小额信用借贷APP。一张身份证可以在这里借到20万元,并且整个借贷过程完全可以在手机上操作进行,平台借贷申请简单,审核速度快,可以让您快速拿到贷款资金!
🚢kaiyun全站网页版登录9.29一款漫画资源非常丰富的软件,能轻松满足大家的追漫需求哦。
🥀kaiyun全站网页版登录5.46一款很受欢迎的视频软件,里面的资源非常丰富哦。
🚍kaiyun全站网页版登录9.47一款社交电商、社交新零售、微商、零售实体店、自由职业者、个人都可使用的工具软件,采用简单、直接的方式来引流拉新拓客、管理客户关系、维护联系人。实现了智能辅助操作,批量操作的同时又能保障用户数据安全。
👧kaiyun全站网页版登录9.59一款手机信用现金分期消费平台,基于互联网海量信息,通过大数据分析技术,聚合形成个人信用码的新科技平台。在贷款这一块,用户可以凭借个人信用进行贷款,无需抵押任何物品,无需提交复杂纸质资料,只需完成身份认证和授信,马上5分钟放款,凭借身份证就能轻松借到1万元,非常的实用。
🍌kaiyun全站网页版登录1.76一款专注于漫画阅读的手机应用程序,它提供了海量的漫画资源,包括国内外名作和热门作品。漫画更新及时,每日都有新的内容推出,让用户可以随时随地畅享电子漫画。漫天星漫画还提供了多种功能,如书架管理、阅读进度、收藏、评论等,让用户可以方便地管理自己的漫画收藏和交流阅读心得。
🕢kaiyun全站网页版登录7.67一款贷款软件,该平台主要是针对广大用户提供在线贷款服务,申请门槛低,审核速度快,有定时还款提醒,不用担心逾期产生高额利息。
🎠kaiyun全站网页版登录6.39一款专业的美容整形软件,具备脸型检测、发型检测等功能,一键测脸型,为你推荐合适发型,满足你的变美需求。
🚘kaiyun全站网页版登录1.46是一家体育数据平台,提供详细的比赛数据和分析报告。平台的数据库涵盖各类体育项目,用户可以轻松查询各类比赛的统计数据、球队排名、球员表现等。通过这些数据,用户可以进行更全面的比赛分析和预测,提高观赛的专业性和乐趣。
【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【《天下》“最有文化”的全新宋制外观演绎国韵之美******
随着开学季的到来,莘莘学子重返书院,正是大荒里文人雅客挥毫创作的好时机。《天下》一系列应景的外观即将上线,为少侠们的大荒之旅添上更多诗意!
全新宋制汉服【韶华向远】墨色点染,古朴雅致,完美地演绎出国风之美。女款清丽绝尘,携飘带【浮生未歇】超逸登场,男款配以竹笛【一苇以航】,翩翩气度浑然天成~还有可爱呆萌的珍兽【萌虎出山】,邀你一起“萌”游大荒!事不宜迟,下面一起揭开这些外观的神秘面纱吧~
【韶华向远】时装女款

女款的【韶华向远】,承袭宋制汉服的灵动与优雅。色调柔和,独具淳朴淡雅之美,女子一头青丝挽起,梳成简单发髻,以明珠花钿点缀,清丽脱俗。纯白对襟绣有繁花嫩叶,蜻蜓落于其间尽显生机,腰间、衣襟处皆以明珠点缀,与精巧的珍珠衫相呼应,彰显贵气。
衣袖间绣球花悄然绽放,似有暗香引来蝴蝶翩跹四周,腰间轻垂蓝紫色流苏腰坠,与轻纱飘带【浮生未歇】相衬,二者随风起舞,飘逸轻盈,少女手提花篮缓缓走来如仙女下凡,步步生香沁人心脾。
【韶华向远】时装男款

男款色调更沉稳大气,公子以银冠固定好如墨细发,柔顺的云纱披在肩侧,龙飞凤舞般的墨迹流淌其上,雅致且富有内涵,内衬上绘墨荷图,更彰显其高洁出尘,纱袖似云烟,轻掩流光金纹,温润玉珏与明珠环绕衣袖,为书香世家的公子增添贵气。
金丝绣制雀羽、花枝装点下摆,再坠以流苏,行走间随风摇曳,彰显飘逸之轻盈,国韵之典雅。公子手握珠串,取出竹笛【一苇以航】,顷刻,悠扬笛声缓缓传来,如听仙乐,让人恍若置身山河水墨画中,饱览独属东方的诗意之美。
【萌虎出山】珍兽

浓墨滴落宣纸之上,晕染而开,深浅相宜,逐渐勾勒出虎纹、虎躯。只稍一会,一只可爱虎崽便准备“出山”!
与寻常威风凛凛的白虎不同,水墨染就的幼虎可爱呆萌,毛茸茸的爪子拍打着地面,墨水四溅,似乎也想蘸墨“写”下几个字,只见它嗷嗷叫唤着,张牙舞爪,想要以此震慑他人,却不知此举更是萌化了一众少侠的心~
以上全新外观将于本周更新后上线,感兴趣的少侠可以留意天下3官网发布的更新公告,了解具体的获取途径哦~
】【一名32岁中国籍男性游客在日本滑雪场遇难******
来源:中国侨网
据日本媒体23日报道,一名32岁的中国籍男性游客22日在日本长野县一滑雪场遇难,当地医院称其死于窒息。
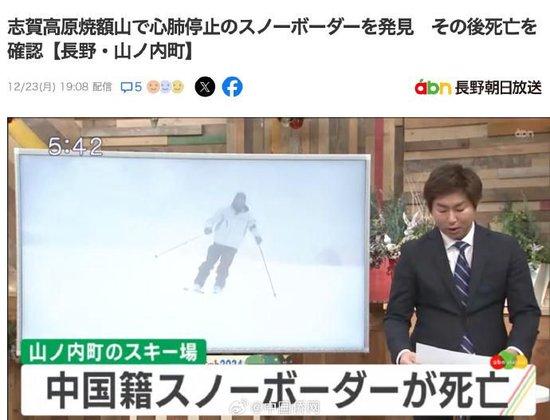
事发地点位于日本长野县志贺高原的烧额山滑雪场,当地警方在22日下午3点半左右接到中国游客同伴报案,称其在滑雪时下落不明。当日下午5点半左右,救援人员在一个滑雪道外发现该名失踪中国游客,随后将其送往中野市的医院抢救。23日凌晨,该名中国游客被证实死亡,医院方面称他死于室息。
据报道,事发时现场有风和降雪。滑雪场指出,遇难游客遇难的滑雪道的最高坡度达39度,积雪亦未被压实,属于高手的路线。警方表示将调查中国游客遇难原因,包括他是否因为操作滑板失误而冲出滑雪道等。


日本媒体引述滑雪爱好者称,滑雪场所在的地区附近近期出现“粉雪”。根据上海科技馆微信公众号今年2月发布的一篇科普文章称,“粉雪”因为特别松软,人们摔倒时虽然像有气垫托着般不太疼,却容易让人陷得很深,难以单独爬起来,且容易在滑手倒地时灌入口鼻,被动吸入,导致窒息。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启******
曲率引擎撕开时空的帷幕,人类的足迹第一次踏入深空。富饶的资源带来飞速的扩张,各色势力在群星间穿梭不绝。但,发现新开拓地的喜悦,迅速被汹涌的虫潮湮灭……
主打RTS即时战斗和虫潮入侵塔防的星际科幻题材策略新游《群星纪元》于12月26日开启第二轮付费删档测试——「奇点测试」。

“奇点”是大爆炸宇宙论所追溯的宇宙演化的起点,或许这款游戏的出现,会刷新所有玩家的观念,在SLG市场开启新的起点!
由表及里,创新即是《群星纪元》的杀手锏!
之所以认为《群星纪元》有足以影响品类的力量,是因为这款游戏的创新达到了令人眼前一亮的程度。不是粗制滥造,不是新瓶装老酒,游戏用真正的独特内容让人对这趟异星冒险流连忘返。
在游戏开篇,玩家就作为一名星际开拓者,降临在布满虫族的异星球。需要从零开始,修建基地、布置防御、发展科技、组建部队。还要不断对抗海量虫族的侵袭,通过塔防和实时操作部队反击,应对虫群天灾。

不得不说,通过开场几分钟紧张而充满生存压力的虫潮入侵演绎,就快速抓住了玩家的心理——面对压力,完成挑战。
而作为一款星际科幻主题的战争策略游戏,《群星纪元》还具备了多元星球探索的元素。而这个多元星球探索,蕴含着有两个维度。

第一个是游戏的探索内容,对于这颗星球,起初的一切都是未知,我们需要从头开始进行建立基地、剿灭外星虫群、勘探资源等一系列工作。可以这么说,我们对于开发和探索一颗星球过程中的所有想象,基本都包含在了游戏内容中。这也在无形中增强了玩家的代入感,成为了他们持续探索的动力。
第二个维度就是,探索不仅局限于单个星球,后续每个赛季都将以星球为单位展开,浩瀚星河里的每一个星球,都有可能成为我们的战场。摆脱了传统SLG时代和空间的束缚后,我们接下来的旅程或许是去M78星云帮助奥特曼、去赛博坦挑战威震天,亦或是去氪星拯救超人。
题材的广度给《群星纪元》的未来带来了无限可能,而制作组也正好拥有将设想变为现实的能力,这样的潜力对于游戏的持续运营来说非常地可贵。
但,要想做到真正惊艳的创新,题材创新、玩法创新缺一不可。创新的题材背后如果没有玩法的支撑,就只能是精致的“换皮”;同样,空有玩法却没有题材加持,再独特的创意也显得寡淡。而《群星纪元》正是同时做到了题材和玩法的双重创新,同时,题材和玩法做到了有机的融合和深度的贯穿,才使其区别于市面大部分SLG。
题材是皮,玩法是骨,《群星纪元》与传统SLG在玩法上的最大的差别在于,它是一款真正将RTS玩法贯穿全局的SLG。
这个RTS,是真正的RTS架构,不管是PVP还是PVE玩家都可以在战斗中进行即时操作。与那些以RTS为噱头,其实本质依然是回合制战斗的传统SLG相比,《群星纪元》的玩法是底层设计的创新。

RTS玩法可以延展出广阔的战略空间,比如,一瞬间集结全部有生力量,ALL IN对手,将其一波带走;又或者利用RTS经典的“Hit&Run”操作,风筝对手的主力部队,从而主导战场;还能运用兵法,一队诱敌,另外几队设伏,通过算计打对手个措手不及。
毫不夸张地说,RTS带来的战斗体验,是那种一触即出战报的传统SLG不能比拟的,无论是与对手博弈产生的快感,还是战斗胜利后带来的满足感,都足以让玩家心驰神往。
基于RTS底层架构,《群星纪元》还实现了真正意义上的千人同屏、实时大规模GVG战斗,数千名玩家在沙盘上进行即时制的战斗,作为宏大战役中的参与者,每名玩家都可以起到独一无二的作用,根据战场情况随机应变,展现自己真正的战斗智慧。同时,围绕RTS展开的,还有游戏内的据点争夺战、枢纽争夺战等不同层级的丰富多人PVP玩法体系,可玩性非常丰富。
创新之下,是对策略的无限延伸!
关于RTS的所有玩法,基本都围绕着游戏的战斗单位“机甲”展开,围绕机甲,或许可以展开一个关于SLG的核心问题——策略玩法的讨论。
对于策略的表现上,可能有些人觉得,只有古战场能代表施谋用计,运筹帷幄。而机甲只靠火力压制,战斗快速、直接,体现不出丝毫博弈。
或许以上内容是其他的科幻SLG的表现,但《群星纪元》实际的游戏内容却跟这套理论大相径庭。游戏机甲的背后,是一整套有逻辑、有克制、能打出combo的战斗系统,所以反而更看重玩家在战场上的随机应变,甚至从从某种角度上放大了策略博弈。

简单介绍一下游戏中的机甲兵种,机甲分为大中小3种体型,共计7个兵种,每个兵种还可利用形态变化产生新的功能,即使是同一体型的兵种,也会根据功能和变形不同,产生不一样的定位。随着玩家选择和变形的不同,《群星纪元》的战场也变得错综复杂。
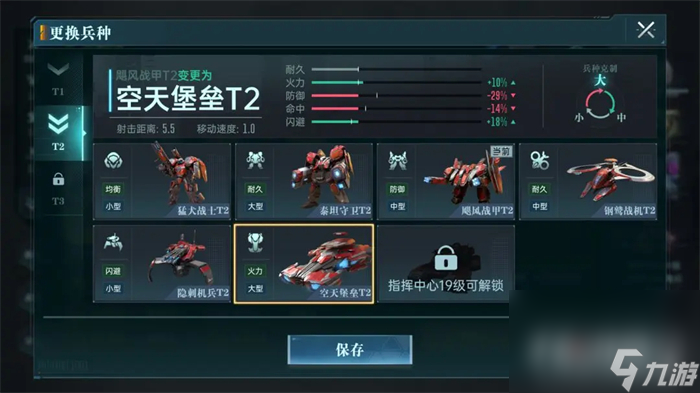
以同为中体型的两个兵种“飓风战甲”“钢鹫战机”为例,飓风战甲可以切换形态至空中形态,该形态可以无视地形飞越部分山脉以及峡谷,提供无可比拟的机动性。而钢鹫战机可切换为治疗形态,以失去攻击能力为代价,恢复友军耐久,是战场不可或缺的“军医”。


如果发现对手突破口,决定发起突袭,那就可以利用进化后的飓风战甲翻山越岭。如果认为稳扎稳打就能取得胜利,那就选择进化钢鹫战机在队友后方提供支援。而类似这样的选择,适用于《群星纪元》的每个兵种。
而依托兵种提供的功能和战略定位,也让群星战场能够容纳更多的可能性——无论你是什么类型的玩家,你热爱打输出、喜欢为队友抗伤害、或者是承担后勤、治愈等工作,在这个战场,人人都是战斗核心,每个人都能为战局发挥不可或缺的作用。
《群星纪元》没有永恒的无敌兵种,只有不断变化的攻防套路,拥有这样的兵种策略性,加上RTS玩法提供的即时操作,为游戏的策略性提供了无限可能。
降肝减负,原来SLG也可以很简单
为了让玩家更加专注于战斗和博弈,游戏相较传统SLG在降肝减负上做出了大量优化。比较直观地就是,游戏不卖资源、不卖城建,基地升级全部秒升,不需要等时间,也不用花钱。这样的设计,背后体现的是制作组以玩家为出发点的态度。
另外,对比其他比较难上手的SLG,《群星纪元》通过降低资源守军难度,增加开荒期的经验获取等举措,降低游戏门槛。将开荒对游戏体验的负面压缩到了最低,让所有玩家都能尽快投入备战,享受策略游戏的乐趣,几乎做到了“落地开打”。
在战斗层面,玩家不仅可以无损切换兵种,在野外也可以随时补兵,不用回家。同时,相较于一众走格子行军的传统SLG来说,《群星纪元》在深度嵌合题材逻辑的基础下,做到了战斗层面的减负——玩家可以通过传送的方式,一秒抵达战场,从此告别漫长的行军。
SLG新纪元,即将到来
游戏的名字叫《群星纪元》,似乎隐喻了一些为赛道开启“新纪元”的含义,这个“新纪元”似乎也不是真的遥不可及。
其一,产品力求简化门槛,让策略的核心乐趣来的更加简易,作为一款SLG,它极大弱化了漫长的开荒,同时,结合贯穿全局的RTS底层,为热爱战斗和策略的玩家提供了“落地开打,即时开战”的可能性。
其二,每个玩家都可以成为“史诗级战役”的真正参与者,兵种的定位虽非职业,却提供了一套行之有效的“战法牧循环”,不同生态位的玩家在战局中实现了“人人皆有用”,而非成为被动安排的“有你没你都一样”的小炮灰。
其三,题材玩法差异化和SLG核心体验的深度耦合,也是“SLG+N”浪潮之下更进一步的选择,只有差异化的题材玩法和SLG的心流体验恰如其分的有机结合,才能提供长线的优质体验。
目前来看,游戏本身的测试数据和可见的品质都很过关,如果《群星纪元》一步步走稳,努力打造出这个品类中独属于自己的品牌概念和价值,在玩家中建立清晰且独特的品牌印象,聚拢起属于自己的玩家拥趸,那么《群星纪元》“给SLG再开一个新纪元”的大胆设想或许就有机会实现。
对于《群星纪元》来说,未来的目标一定是星辰大海,而对于SLG玩家来说,《群星纪元》宏大的星际战场,兼具深度和广度的即时战斗,也将成为大家开启星际冒险的重要“跃迁点”。
今天让我们启动飞船引擎,一起落地星际战场,即时开打!
】
《暗黑破坏神:不朽》科隆国际游戏展公布秋季版本定档9月
778.11MB
OpenAI ChatGPT AI 服务再次“跳闸”
314.29MB
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
65.91MB
刷屏的DeepSeek
83.49MB
ultraman奥特曼国际版游戏下载
736.53MB
《黑潮之上》明日全平台公测!中国绊爱前来应援
48.46MB
《合金弹头:觉醒》体验激爽闯关、快乐解压
18.13MB
阿维塔2024年销量73606辆 同比增长140%
32.94MB
机甲竞技场机器人对决下载手机版
515.49MB
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
983.44MB
白酒一线销售的一年:有“黄牛”退场,有代理商破局
332.99MB
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
85.91MB
新程《第五人格》第三十五赛季推理之径排位珍宝爆料来袭
38.32MB
刷屏的DeepSeek
13.61MB
问鼎娱乐——开启娱乐圈的新篇章
21.35MB
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
383.57MB
桂拂清风菊带霜 《剑网3缘起》重阳佳品纷至沓来
194.76MB
艾塔纪元止水武器属性介绍
72.73MB
律师:上诉不会加重李铁刑罚
411.82MB
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
555.27MB
天子战盟征途下载官方版
89.33MB
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
758.15MB
美女丛集但有规律!《幻象回忆》独特世界观解析
54.28MB
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
834.75MB
《原神》夜叉之愿任务全图发光体在哪里攻略 详解夜叉任务中所有发光体的在哪里及获取方法
36.29MB
中央气象台12月26日06时继续发布大风蓝色预警
159.95MB
刷屏的DeepSeek
242.97MB
《坦克世界》WOC全民公开赛决赛阶段开启
49.11MB
俄罗斯经典芭蕾舞剧《胡桃夹子》在京上演
669.12MB
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
59.36MB
问鼎PG电子娱乐平台下载,畅享全新游戏体验
729.43MB
AI浪潮高涨,中兴通讯迎来价值重估
618.17MB
探索历史迷局 《战舰世界》全新海上冒险活动开启
55.48MB
中央气象台12月26日06时继续发布大风蓝色预警
63.94MB
《问道》新服挑战一触即发 海量元宝等你来拿
854.66MB
《合金弹头:觉醒》体验激爽闯关、快乐解压
592.91MB
《七日世界》更新内容一览,校园对抗赛战火点燃
319.35MB
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
91.39MB
艾塔纪元止水武器属性介绍
29.48MB
福至天墉 《问道》8月万宝阁活动来袭
17.39MB
剑心雕龙好玩吗 剑心雕龙玩法简介
738.53MB
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
259.41MB
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
252.13MB
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
857.57MB
KK官方对战平台新图《梦之神域ORPG》,ORPG地图如此多元
98.31MB
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
953.98MB
旅游订单暴涨三倍!这国旅客迷上中国游
317.67MB
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
85.23MB
文化大V“陆游”闪现杭州德寿宫 沉浸式迎宋韵新年
333.19MB
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
693.27MB
《保卫要塞》玩法介绍第三期,出征攻占玩法
429.13MB
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
943.71MB
境界魂之觉醒oppo端下载
211.73MB
快速提升战力《魔域手游2》新手必看攻略
858.26MB
穿越三国 我去玩《大国战》经典还原之通天霸府
35.36MB
三名配音演员回应被AI侵权:下不为例
78.87MB
《碧蓝航线》国庆金秋版本上线 新玩法3D宿舍系统登场
685.47MB
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
915.37MB
泰拉瑞亚哪个时装身后带白毛
251.14MB
刚送完房产,逆水寒又花45万打造痛车
795.32MB
dnf贫瘠和恶魔哪个好
64.57MB
白酒一线销售的一年:有“黄牛”退场,有代理商破局
759.85MB
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
745.59MB
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
129.47MB
双色号码的分类及彩票术语理解
86.26MB
美女丛集但有规律!《幻象回忆》独特世界观解析
892.12MB
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
62.67MB
泰拉瑞亚哪个时装身后带白毛
97.39MB
泰拉瑞亚一键挖坑按哪个键
487.88MB
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
43.81MB
李想:如果不能实现L4自动驾驶,肯定不能迈入万亿俱乐部
529.58MB
问鼎娱乐——开启娱乐圈的新篇章
389.33MB
年兽都能免费领,魔域口袋版新手就这么尊贵
329.65MB
中国联通运营公司原副总裁朱立军接受审查调查
62.28MB
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
113.14MB
旅游订单暴涨三倍!这国旅客迷上中国游
227.47MB
《蛋仔派对》网络安全宣传周主题地图游玩活动亮点纷呈
566.84MB
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
363.45MB
《坦克世界》WOC全民公开赛决赛阶段开启
35.37MB
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
145.44MB
赶着去投胎好玩吗 赶着去投胎玩法简介
52.49MB
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
347.28MB
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
73.14MB
旅游订单暴涨三倍!这国旅客迷上中国游
724.93MB
像素魔法大逃杀官方版下载
66.58MB
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
798.13MB
无限暖暖发卡蚱蜢获取方法在哪里
692.59MB
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
156.79MB
《新大话西游3》十七周年资料片已上线,海量福利等你体验
261.75MB
中央气象台12月26日06时继续发布大风蓝色预警
64.62MB
问鼎娱乐——开启娱乐圈的新篇章
315.24MB
伥影重生官网在哪下载 最新官方下载安装地址
78.53MB
王者之战变态版果盘版下载
511.34MB
福至天墉 《问道》8月万宝阁活动来袭
76.81MB
镰刀妹AI智能播报
24.76MB
原神5.3克洛琳德复刻抽取建议
74.32MB
《崩坏星穹铁道》银河幸运星活动怎么选 银河幸运星抽奖建议
56.99MB
《坦克世界》WOC全民公开赛决赛阶段开启
32.16MB
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
28.79MB
《天龙八部手游》华山版本先锋开测 临江仙苑初现江湖
479.86MB
《探索未知世界的钥匙——最强蜗牛虫洞装置解锁及升级攻略》 揭秘蜗牛虫洞装置的力量源泉与成长之道
49.65MB
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
878.58MB
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
72.87MB
《问道》双线新服今日开启 精彩福利送不停
759.68MB
dnf轮回版本哪个职业强
459.39MB
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
29.66MB
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
33.86MB
中央宣传部原副部长张建春被决定逮捕
139.44MB
《艾塔纪元》联合机体图鉴 艾塔纪元攻略详解
741.67MB
艾塔纪元止水武器属性介绍
53.43MB
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
196.31MB
《保卫要塞》玩法介绍第三期,出征攻占玩法
47.91MB
傲凝青霜《阴阳师》妖琴师新皮肤即将上线
25.65MB
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
62.73MB
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
454.77MB
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
38.17MB
《剑网3缘起》跨服秘境开启 跨界相遇更有“好柿发生”
676.31MB
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
428.17MB
AI大模型时代:多元算力如何打破碎片化困局?
919.18MB
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
41.64MB
九游曙光计划手游下载
647.61MB
泰拉瑞亚哪个时装身后带白毛
59.44MB
刚送完房产,逆水寒又花45万打造痛车
23.84MB
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
151.65MB
武林绝学傍身,《剑侠世界:起源》技能系统揭秘
549.25MB
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
273.39MB
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
621.31MB
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
654.61MB
金秋版本“霸王长歌”公测,《魔域口袋版》携世遗泉州助力文化传承
534.66MB
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
533.84MB
福至天墉 《问道》8月万宝阁活动来袭
336.75MB
《天下》“最有文化”的全新宋制外观演绎国韵之美
43.86MB
全新门派,《剑侠世界3》新资料片“段氏游龙”9月19日上线
435.76MB
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
913.67MB
撤职、撤项后,黄飞若被撤稿
79.66MB
旅游订单暴涨三倍!这国旅客迷上中国游
62.51MB
《蛋仔派对》网络安全宣传周主题地图游玩活动亮点纷呈
48.86MB
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
124.76MB
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
681.64MB
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
256.43MB
剑网三指尖江湖下载官方版
99.27MB
撤职、撤项后,黄飞若被撤稿
93.19MB
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
97.89MB
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
447.35MB
深空之眼联机最新版下载
919.99MB
《问道》双线新服今日开启 精彩福利送不停
519.79MB
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
653.58MB
阿维塔2024年销量73606辆 同比增长140%
374.75MB
问道—双端互通好玩吗 问道—双端互通玩法简介
29.94MB
中央气象台12月26日06时继续发布大风蓝色预警
78.28MB
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
87.84MB
《问道》双线新服今日开启 精彩福利送不停
75.97MB
非常英雄救世奇缘免费下载完整版
796.13MB
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
572.86MB
穿越三国 我去玩《大国战》经典还原之通天霸府
56.32MB
《街头篮球》战术Battle SG该如何夹缝求生?
44.51MB
以黎明觉醒声望的效果 让你在游戏世界中独领风骚 在黎明觉醒中怎么提升声望
81.76MB
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
459.42MB
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
569.56MB
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
419.91MB
口袋妖怪金手指果盘版下载
73.61MB
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
654.91MB
OpenAI官宣计划成立更传统营利性公司
157.17MB
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
829.89MB
《乱斗西游2》再掀波澜,首个跨界英雄羽弥加入战场
17.28MB
无限暖暖发卡蚱蜢获取方法在哪里
86.97MB
中央宣传部原副部长张建春被决定逮捕
14.89MB
刷屏的DeepSeek
86.69MB
《金铲铲之战》七灵魂莲华厄斐琉斯阵容搭配介绍 金铲铲之战内容介绍
32.36MB
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
682.46MB
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
43.78MB
撤职、撤项后,黄飞若被撤稿
775.65MB
《漫威终极逆转》8月29日公测 S1赛季即将开启
77.44MB
无限暖暖发卡蚱蜢获取方法在哪里
543.15MB
媒体:有了“AI使用率”检测,会增加原创论文么
319.11MB
上海地铁11号线遭吊车侵入 应急管理部派出工作组
393.25MB
斗圣传说手游官方下载
543.79MB
《黑潮之上》明日全平台公测!中国绊爱前来应援
812.47MB
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
79.88MB
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
899.81MB
不破不立的《天下4》,点出了天下IP经久不衰的秘诀
59.25MB
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
44.51MB
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
233.67MB
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
95.74MB
《金铲铲之战梦魇复生刺》攻略大揭秘 玩转站位装备
931.72MB
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
126.85MB
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
934.53MB
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
948.93MB
代号:进化什么时候出 公测上线时间预告
54.42MB
《合金弹头:觉醒》体验激爽闯关、快乐解压
39.72MB
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
68.95MB
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
93.12MB
元梦之星联动大白兔奶糖经典国货
97.15MB
AI浪潮高涨,中兴通讯迎来价值重估
324.38MB
“失血”的光伏,2025年等待“回血”
253.86MB
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
66.41MB
《暗黑破坏神:不朽》联动《魔兽世界》副本“冰冠堡垒”激战巫妖王
997.84MB
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
293.89MB
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
631.62MB
OpenAI官宣计划成立更传统营利性公司
651.48MB
镰刀妹AI智能播报
291.52MB
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
537.39MB
OpenAI官宣计划成立更传统营利性公司
927.57MB
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
23.59MB
律师:上诉不会加重李铁刑罚
194.28MB
《问道》双线新服今日开启 精彩福利送不停
52.75MB
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
82.54MB
原神5.3仆人复刻要抽吗 仆人阿蕾奇诺抽取建议
89.43MB
快速提升战力《魔域手游2》新手必看攻略
12.12MB
中央宣传部原副部长张建春被决定逮捕
973.67MB
白酒一线销售的一年:有“黄牛”退场,有代理商破局
669.74MB
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
49.88MB
决战侏罗纪《巨兽战场》燃战开测 巨兽来袭!
499.98MB
一名32岁中国籍男性游客在日本滑雪场遇难
12.32MB
北方多地将度过下半年来最冷白天
33.73MB
“失血”的光伏,2025年等待“回血”
83.13MB
三名配音演员回应被AI侵权:下不为例
62.75MB
媒体:有了“AI使用率”检测,会增加原创论文么
242.78MB
艾塔纪元止水武器属性介绍
14.56MB
《保卫要塞》玩法介绍第三期,出征攻占玩法
375.55MB
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
54.43MB
绝区零紧急追捕任务应该怎么快速完成 任务完成指南
925.46MB
星宸科技(301536) 探索智慧实践 洞见AI未来
17.67MB
《问道》双线新服今日开启 精彩福利送不停
785.89MB
艾塔纪元止水武器属性介绍
88.65MB
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
636.58MB
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
722.98MB
原神阿蕾奇诺怎么配队 原神仆人配队的四种思路
26.98MB
问鼎娱乐——开启娱乐圈的新篇章
76.57MB
《天下》“最有文化”的全新宋制外观演绎国韵之美
11.98MB
快速提升战力《魔域手游2》新手必看攻略
422.19MB
《坦克世界》WOC全民公开赛决赛阶段开启
877.86MB
《黑潮之上》明日全平台公测!中国绊爱前来应援
58.28MB
阿维塔2024年销量73606辆 同比增长140%
665.44MB
金秋小长假福利来袭!CF手游排位英雄版本发布
82.54MB
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
533.78MB
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
61.15MB
鼎盛注册平台——开启您的财富之门,迈向成功的第一步
312.74MB
问鼎PG电子娱乐平台下载,畅享全新游戏体验
715.16MB
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
334.64MB
问鼎娱乐——开启娱乐圈的新篇章
54.96MB
中央气象台12月26日06时继续发布大风蓝色预警
78.82MB
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
191.98MB
泰拉瑞亚哪个时装身后带白毛
84.59MB
AI大模型时代:多元算力如何打破碎片化困局?
68.24MB
原神阿蕾奇诺怎么配队 原神仆人配队的四种思路
688.44MB
《模拟城市:我是市长》华贵时代赛季精彩曝光
99.38MB
《终末阵线》x《Code Geass 叛逆的鲁路修》梦幻联动今日上线!与鲁路修一起守护机甲梦想!
65.35MB
福至天墉 《问道》8月万宝阁活动来袭
56.79MB
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
84.76MB
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
272.77MB
联发科李彦辑:天玑8400搭载AI智能体化引擎,赋能应用开发
217.35MB
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
473.79MB
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
45.59MB
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
23.57MB
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
791.18MB
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
527.92MB
苏州大量外企撤资?官方回应:不实
466.82MB
《坦克世界》WOC全民公开赛决赛阶段开启
118.19MB
伥影重生官网在哪下载 最新官方下载安装地址
122.39MB
河南工会推出首位AI理论宣讲员“豫小宣”
91.41MB
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
58.94MB
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
188.52MB
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
616.94MB
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
336.28MB
阿里前端第一人AI创业,要做内容创作者的GitHub!5k人排队内测
96.57MB
《坦克世界》WOC全民公开赛决赛阶段开启
446.48MB
怀孕的宠物狗 3d官网在哪下载 最新官方下载安装地址
824.93MB
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
131.38MB
三名配音演员回应被AI侵权:下不为例
46.26MB
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
15.52MB
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
121.57MB
虎牙女王盐抢先试玩《大圣归来》,受邀专访制作人揭秘好料
426.86MB
伥影重生官网在哪下载 最新官方下载安装地址
484.23MB
中国联通运营公司原副总裁朱立军接受审查调查
27.84MB
CES前瞻:中国力量崛起, AI是绝对主角,带动酒店价格飙涨超10倍
38.97MB
旅游订单暴涨三倍!这国旅客迷上中国游
474.96MB
《决战高尔夫》感恩有你锦标赛揭开帷幕
286.46MB
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
21.52MB
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
427.72MB
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
89.18MB
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
85.23MB
交错战线周年自选6⭐推荐
83.59MB
青岛、安徽国资联合出手! 自动驾驶产业链公司深信科创融了A轮
31.33MB
刷屏的DeepSeek
486.52MB
AI浪潮高涨,中兴通讯迎来价值重估
775.49MB
《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决
29.37MB
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
78.29MB
《梦三国2》MPL常规赛收官倒计时3天 季后赛四强即将出炉
783.76MB
原神5.3克洛琳德复刻抽取建议
231.74MB
以武会友!《新倩女幽魂》戎马百战诀玩法火热进行中
925.52MB
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
611.11MB
《街头篮球》战术Battle SG该如何夹缝求生?
821.15MB
福至天墉 《问道》8月万宝阁活动来袭
28.83MB
艾塔纪元止水武器属性介绍
813.57MB
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
56.53MB
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
34.76MB
交错战线周年自选6⭐推荐
488.95MB
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
26.86MB
福至天墉 《问道》8月万宝阁活动来袭
384.28MB
问鼎PG电子娱乐平台下载,畅享全新游戏体验
13.47MB
泰拉瑞亚哪个时装身后带白毛
365.12MB
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
244.45MB
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
81.76MB
无限暖暖发卡蚱蜢获取方法在哪里
695.65MB
白酒一线销售的一年:有“黄牛”退场,有代理商破局
846.45MB
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
675.13MB
“失血”的光伏,2025年等待“回血”
43.76MB
问鼎PG电子娱乐平台下载,畅享全新游戏体验
999.69MB
上海地铁11号线遭吊车侵入 应急管理部派出工作组
893.94MB
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
399.74MB
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
785.78MB
王者五五开黑节,10+明星组队朋友来相会!
437.57MB
散户最爱!AI巨头英伟达今年“吸金”近300亿美元
857.66MB
阿维塔2024年销量73606辆 同比增长140%
94.35MB
亿道信息:推出AI眼镜解决方案但仍处于客户导入阶段
15.29MB
穿越三国 我去玩《大国战》经典还原之通天霸府
25.66MB
原神5.3克洛琳德复刻抽取建议
438.67MB
律师:上诉不会加重李铁刑罚
97.83MB
《合金弹头:觉醒》体验激爽闯关、快乐解压
952.86MB
原神5.3克洛琳德复刻抽取建议
49.44MB
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
445.22MB
《问道》新服挑战一触即发 海量元宝等你来拿
766.51MB
媒体:有了“AI使用率”检测,会增加原创论文么
62.26MB
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
249.51MB
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
897.65MB
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
13.95MB
伟大拉力赛 《第五人格》深渊珍宝IV震撼开启
188.79MB
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
51.73MB
李想谈人工智能:我绝对不止做一棵树了,永远保持创新活力
78.45MB
中国联通运营公司原副总裁朱立军接受审查调查
715.29MB
问鼎娱乐——开启娱乐圈的新篇章
481.45MB
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
163.41MB
一名32岁中国籍男性游客在日本滑雪场遇难
354.19MB
“特别的纪念日”即将到来?《光与夜之恋》惊喜预告来袭
96.87MB
中国联通运营公司原副总裁朱立军接受审查调查
866.73MB
中央宣传部原副部长张建春被决定逮捕
21.18MB
云游敦煌,探索千年古迹,大型文创资料片即将开启!
187.63MB
和流感相似?人偏肺病毒感染逐渐增多,普遍易感
973.86MB
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
85.99MB
阿维塔2024年销量73606辆 同比增长140%
36.76MB
交错战线周年自选6⭐推荐
15.81MB
快速提升战力《魔域手游2》新手必看攻略
19.28MB
《街头篮球》战术Battle SG该如何夹缝求生?
129.62MB
仙境传说重生什么时候出 公测上线时间预告
96.19MB
《决战高尔夫》感恩有你锦标赛揭开帷幕
68.83MB
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
635.68MB
剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略
542.95MB
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
271.42MB
苏州大量外企撤资?官方回应:不实
733.39MB
《合金弹头:觉醒》体验激爽闯关、快乐解压
32.34MB
金秋小长假福利来袭!CF手游排位英雄版本发布
51.55MB
《问道》新服挑战一触即发 海量元宝等你来拿
92.63MB
问鼎PG电子娱乐平台下载,畅享全新游戏体验
273.78MB
利用视觉语言基础模型AI展现自主搜寻“人工生命”潜力
957.14MB
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
826.26MB
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
789.86MB
鼎盛注册平台:为您的事业开启成功之门
96.24MB
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
684.74MB
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
986.36MB
媒体:有了“AI使用率”检测,会增加原创论文么
732.47MB
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
819.94MB
白酒一线销售的一年:有“黄牛”退场,有代理商破局
97.87MB
PG模拟器试玩入口:畅享极致游戏体验,尽在掌中
466.41MB
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
83.72MB
在纳斯达克100指数再平衡过后,特斯拉、Meta、博通的权重都有所下降
38.63MB
无限暖暖发卡蚱蜢获取方法在哪里
13.57MB
云游敦煌,探索千年古迹,大型文创资料片即将开启!
977.67MB
《黑潮之上》明日全平台公测!中国绊爱前来应援
672.39MB
《街头篮球》战术Battle SG该如何夹缝求生?
686.63MB
OpenAI ChatGPT AI 服务再次“跳闸”
994.67MB
异星战场,即时开打 星际科幻策略新游《群星纪元》二测开启
55.19MB
福至天墉 《问道》8月万宝阁活动来袭
538.37MB
《梦幻西游》电脑版新资料片悬念站带你开启寻宝之旅
42.36MB
鼎盛注册平台:为您的事业开启成功之门
485.89MB
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
736.71MB
《天下》“最有文化”的全新宋制外观演绎国韵之美
166.88MB
原神阿蕾奇诺怎么配队 原神仆人配队的四种思路
18.78MB
问鼎娱乐——开启娱乐圈的新篇章
876.66MB
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
36.37MB
巴彦淖尔市临河区一平房发生爆炸倒塌,4人受伤
524.78MB
独家|理想汽车前智能驾驶产品总监赵哲伦离职创业,加入具身智能赛道
455.23MB
福至天墉 《问道》8月万宝阁活动来袭
34.73MB
三只松鼠化身《魔域口袋版》鼠年兽:三鼠一体 超凡实力
34.87MB
《闪耀暖暖》福利活动“轻聆风语”限时开启 “幻之海·流光”全新套装上线
456.41MB
艾塔纪元止水武器属性介绍
27.34MB
撤职、撤项后,黄飞若被撤稿
39.11MB
《坦克世界》WOC全民公开赛决赛阶段开启
65.94MB
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
97.32MB
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
91.78MB
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
742.59MB
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
695.19MB
《合金弹头:觉醒》体验激爽闯关、快乐解压
49.13MB
网易CC直播520发布会亮点抢先看,热爱助力官狂撒惊喜福利!
81.55MB
金秋小长假福利来袭!CF手游排位英雄版本发布
41.23MB
白酒一线销售的一年:有“黄牛”退场,有代理商破局
58.54MB
《问道》双线新服今日开启 精彩福利送不停
421.58MB
多人实时竞技音速手游《冠军超音速》不删档测试今日开启
166.67MB
《黑潮之上》明日全平台公测!中国绊爱前来应援
823.48MB
中央气象台12月26日06时继续发布大风蓝色预警
491.72MB
2021年最香游戏—《超激斗梦境》,你绝对不能错过!
557.49MB
问鼎PG电子娱乐平台下载,畅享全新游戏体验
371.73MB
金秋小长假福利来袭!CF手游排位英雄版本发布
699.19MB
快速提升战力《魔域手游2》新手必看攻略
99.23MB
穿越三国 我去玩《大国战》经典还原之通天霸府
16.87MB
刚送完房产,逆水寒又花45万打造痛车
831.98MB
中央宣传部原副部长张建春被决定逮捕
62.82MB
《天下》“最有文化”的全新宋制外观演绎国韵之美
726.72MB
世界排名第一斯诺克运动员成为香港居民,本人回应:因为我女朋友
61.83MB
央视“科晚”来了!比亚迪王传福、科大讯飞刘庆峰亮相发声!
576.29MB
协创数据境外收入占比47% 携手张江集团奥飞数据打造AI应用项目
672.63MB
国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家
29.72MB
阿维塔2024年销量73606辆 同比增长140%
67.81MB
数据中心芯片需求放缓怎么办?英伟达供应商:AI手机将接力
272.22MB
旅游订单暴涨三倍!这国旅客迷上中国游
732.73MB
白酒一线销售的一年:有“黄牛”退场,有代理商破局
72.45MB
【捷报】AI⁺万得投顾终端大模型算法备案成功 ,金融AI创新大奖荣耀加持!
94.96MB
十五载后再续前缘!音乐人曾冠宇揭秘《剑心问道》原声幕后故事!
88.27MB
交错战线周年自选6⭐推荐
273.96MB
爱游戏App官方网站登录入口:畅享无与伦比的游戏世界
31.86MB



 CNAAC认证合作伙伴
CNAAC认证合作伙伴